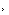|
索爱小逃妻AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:;
生成式人工智能研究实验室(GAIR,主页:)由上海交通大学刘鹏飞副教授2023年4月回国创建,是国内首个聚焦于生成式人工智能的高校研究组。汇聚了来自于CMU、复旦、交大(ACM班、IEEE试点班等)等顶尖高校的年轻本硕博人才。实验室专注于三大核心领域:大模型基础研究、对齐系统和社会影响,致力于培养顶尖人工智能人才(具有原创、批判精神等)、开发尖端的生成式人工智能技术,赋能人类解决复杂问题,提升人类生活质量。
自LLaMa自回归文本生成大模型耀眼登场以来,整个AI界翘首以盼,期待一个能够真正实现原生、自回归图文生成的开源大模型。17个月的漫长等待,我们见证了以文本为核心的LLaVa的崛起,目睹了基于Diffusion的Dalle的惊艳,却始终未能一睹那个能够完美融合文字与图像的模型真容。
直到今天,Anole的诞生,终于填补了这一空白,满足了AI研究者和开发者的殷切期盼,让每个人都可以用开发LLaMa的方式去开发多模态大模型。
想象一下,你只需敲击几个键盘,就能唤醒一位虚拟大厨,为你展示一道完美煎蛋的每一个精妙步骤。这不再是科幻,而是由上海交通大学GAIR团队带来的创新成果――Anole模型。
Anole是多模态大模型领域发展的一次重要技术突破,作为全球首个完全开源、自回归、原生的(文本与图片一起从头训练)多模态大模型。无需复杂的扩散模型,Anole凭借纯粹的token自回归预测,就能实现文字与图像的无缝交织。如图所示,当你在Anole的界面上输入用图片和文字讲解煎鸡蛋的每一步时,它会瞬间化身为你的私人厨艺导师。一系列生动形象的步骤图随即呈现,每一幅图都配有清晰明了的文字说明,仿佛一位耐心的大厨在为你量身定制教程。
这仅仅是Anole众多强大功能中的一个。接下来,让我们深入了解这个创新的多模态生成模型及其背后的技术。
Anole是首个能够实现交错图文生成的开源、自回归、原生训练的大型多模态模型(无需使用稳定扩散技术)。虽然它建立在Meta 开源的Chameleon[1]的优势基础之上,但Anole新增了生成连贯的交替文本和图像序列这一复杂任务。通过使用精心构建的的约6,000张图像数据集进行创新性微调,Anole以最少的额外训练实现了出色的图像生成和理解能力。这种高效的方法,加上其开源特性,使Anole成为加速多模态AI研究和开发的催化剂。初步测试表明,Anole具有卓越的能力,能够遵循细致入微的指令,产生高质量的图像和交错的文本-图像内容,与用户提示密切吻合。
除了具备常规多模态模型的“文本生成”和“多模态理解”能力外,Anole还展现了出色的图文交错生成和文本生成图像的能力。
近年来,多模态AI技术取得了显著进展,Meta AI推出的Chameleon模型便是其中的代表。Chameleon通过在预训练期间融合图像和文本语料的方法,展示了在视觉和语言整合方面的潜力。然而,尽管Chameleon具有突破性,其图像生成的关键网络参数并未开源,限制了其进一步的研究和实际应用。
Chameleon的预训练数据本身就包含了文本和图像两种模态,理论上赋予了它图像生成的能力。我们的目标是在不影响其文本理解、生成和多模态理解能力的前提下,激活这种能力。为实现这一目标,我们冻结了Chameleon的大部分参数,仅对transformer的输出头层中与图像token ID对应的logits进行了微调。
:通过创新的局部微调方法,只调整不到40m参数,在短时间内(8 个 A100 GPU 上大约 30 分钟),便成功激发出Chameleon的图像生成能力,使研究人员和开发者能够充分利用并基于Chameleon的架构进行后续的多模态AI研究工作。
:仅需5,859个图片样本便可有效激发Chameleon的图像生成能力,展示了在大型多模态模型中恢复复杂功能的高效性。
:提供了一整套用于微调、推理Chameleon和Anole的代码库,显著降低了开发和实验的门槛。
:提供了丰富的数据资源和详细的教程,旨在帮助各级别的研究人员更容易上手和实验。
值得注意的是,GAIR团队已经对 Anole项目进行完全开源(提供了开源的模型权重、推理与训练代码和详细使用教程),以确保每个感兴趣的研究者都能重现这些结果,可以微调模型,创建自己的风格变体。该项目旨在建立和共享一个具有完整图文理解和生成能力的多模态模型,并通过完全开源实现多模态技术民主化,让更多人可以加入多模态大模型的开发中。
更重要的是,Anole 为学术界开启了一系列重要且富有挑战性的研究方向。具体而言:
它为探索统一的基于分词器的多模态模型(token-based)的性能上限提供了新的途径,使得与扩散模型 (diffusion-based) 等方法的比较成为可能。
同时,它推动了高效交错文本-图像解码技术的发展,这对实时应用至关重要(比如动漫生成、教材生成)
此外,Anole 为探索这类复杂模型的最优微调策略创造了契机,并提出了如何确保生成图像安全性和伦理使用等亟待解决的问题。
从根本上说,Anole 不仅是一个强大的工具,更是为未来研究提供了沃土,为 AI 社区构建了一个稳固的资源和基础设施平台,使其能够在此基础上不断创新和发展。这种开放的方法有望加速多模态 AI 的进展,有可能带来突破性成果,而这些成果在过去因缺乏先进模型和技术的获取途径而难以实现。
|
 返回首页
返回首页 
 栏目文章
栏目文章