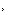|
����ʥѩ�ڹ�Ĥ�����Կ�ʼ���ǵ��ó����𣿡�Spot ��ò�ط���ѯ�ʣ�����������������ǣ���
������һ�����·�������Ƶ���ʿ�ٶ���չʾ�˽��������� LLM ���ɵijɹ�����Spot ���������Ÿ���ñ������С���ӣ����Ŵ��۾���Ӣ�������������˲ι۹�˾����ʩ��
����Ϊ���� Spot �ܹ������ڡ�����ʿ�ٶ�����˾ʹ�� OpenAI �� ChatGPT API �Լ�һЩ��Դ LLM ��ѵ����Ȼ��Ϊ�������䱸�����������������ı�������ת���Ĺ��ܡ�
�����������ܿ������ڷ���������ͬʱ��Spot ��ͣ�ſ�����͡�����������������˵����
������ʿ�ٶ�����˾��ϯ��������ʦ Matt Klingensmith ��ʾ����Spot ������ʹ�� VQA ģ����Ϊͼ��������Ļ���ش��й�ͼ������⡣
������Spot �������������𣺡��ҿ�����һ���ά��İ��ӣ�����һ�Ⱥܴ�Ĵ�������
����LLM ��ν�ġ�ӿ����Ϊ����ʹ���ܹ�ִ�мȶ�ѵ��֮�������������ˣ����ǿ��������ڸ���Ӧ�á���ʿ�ٶ����ŶӶԴ˵�̽���Ǵӽ������쿪ʼ�ģ������ڻ�����Ӧ����ʹ�� LLM ����һЩ������֤��ʾ����Щ�뷨����һ���ڲ��ڿ������ɻ�м�����չ��
�����ر��ǣ����Ƕ� Spot ʹ�� LLM ��Ϊ�������ߵ���ʾ�ܸ���Ȥ���Ŷӵ������Դ�� LLM �ڽ�ɫ���ݡ������Ļ���ϸ����γɼƻ��ͳ��ڱ��������Է���������������Լ����ڷ����� VQA ģ�ͣ���Щģ�Ϳ���Ϊͼ�����ӱ��Ⲣ�ش��й�ͼ��ļ����⣩��
�����������������ǽ������ʹ�� Spot �� SDK ��������һֻ�����������Ρ��������µĹٷ������У���ʿ�ٶ����ԡ�Spot ����������ļ�����������ϸ���ܡ�
������Ϊ���Σ�Spot �ġ��Ĵ��߶����������ֳɵģ�Spot SDK Ҳ�����û�ʵ�ֶԻ��������Զ��塣��Spot ��������۲컷���е����壬ʹ�� VQA ����Ļģ�Ͷ������������Ȼ��ʹ�� LLM ����Щ����������ϸ˵����
�����Ŷ��� Spot �ռ�����ά��ͼ�ϱ�ע�˼�̵������������˻���ݶ�λϵͳ��������λ�õ��������������봫�����ṩ������������һ������ LLM��Ȼ��LLM ����Щ���ݺϳ�Ϊ������硸˵�������ʡ�����ȥ����ǩ���ȡ�
������ͼ�ǡ�Spot ���������εĽ�����������ά��ͼ��Ϊ LLM ��ע��λ�ã�1 ����ʾʵ���� / ��̨��2 ����ʾʵ���� / ���ţ�3 �Dz���� /old-spots��4 �Dz���� / ͼ����5 �Ǵ�����6 ���ⲿ / ��ڡ�
�������⣬LLM �����Իش�ι��ߵ����⣬���ƻ���������һ��Ӧ�ò�ȡ���ж������Խ� LLM ����Ϊһ��������Ա�������˴��½ű�֮��Ҳ�ܹ���ʱ��հס�
����������ϵķ�ʽ��ַ����� LLM �����ƣ�������� LLM ���ܴ����ķ��գ�������֪��LLM �Ļþ������أ���������һЩ���������Ƕ��ǵ�ϸ�ڣ��Һ�������ι۹����У�����̫ǿ����ʵȷ�ԡ�������ֻ���Ĵ��߶���̸�������������������һЩ�����ԡ������Ժ�ϸ��ɡ�
����Ӳ�����棬�����ǡ���Ƶ���������ܣ�Spot �����������ʾ�����������ι��ŵ����ʺ���ʾ���Ŷ��� 3D ��ӡ��һ�� Respeaker V2 �������ķ���֧�ܣ�����һ������������˷磬������ LED ָʾ�ƣ�ͨ�� USB ���ӵ� Spot �� EAP 2 ��Ч�غ��ϡ�
���������˵�ʵ�ʿ���Ȩ���·Ÿ�һ̨������ԣ�̨ʽ���Ի�ʼDZ����ԣ����õ���ͨ�� SDK �� Spot ����ͨ�š�
�������� Spot �߱��˲����ĶԻ�������ChatGPT �Ի����˼��䡸����Ŀ�����ͨ�����ĵ� prompt ����ʵ�ֵġ����������������������� ChatGPT �����������ڡ���д python �ű�����һ�С����Դ��� prompt ChatGPT����ʿ�ٶ����Ŷ���ע�͵���ʽΪ LLM �ṩ��Ӣ���ĵ���Ȼ�� LLM ��������� python �������������LLM ���Է������� SDK������ÿ���ص㵥�����������ξ����ͼ������˵�������������⡣
��������֮��ʿ�ٶ����Ŷ��� LLM �ṩ��һ���й�����Χ���ݽṹ����Ϣ�ġ�״̬�ֵ䡹��
���������һ�� prompt��Ҫ�� LLM ִ��ijЩ�������ڱ����У����� API ���������֮һ��
�����Ŷӵó��Ľ����ǣ����мǼ�����Ҫ�����dz���Ҫ����������Ҫִ�еĴ������������ڻ�������Ӧʱ���ֿɿصĵȴ�ʱ�䡣
����Ŀǰ��OpenAI �Ѿ��ṩ��һ�ֽṹ���ķ�ʽ��ָ�� ChatGPT ���õ� API�������� prompt �������ṩ������Щϸ���Ѿ����DZ�����ˡ�
������������Ϊ���� Spot ����ںͻ�����������ʿ�ٶ��������� VQA ������ת�ı����������ǽ� Spot �Ļ�е������ͷ��ǰ������ͷ���� BLIP-2������ VQA ģ�ͻ�ͼ����Ļģ�������С���Լÿ������һ�Σ����ֱ������ Prompt��
����Ϊ���û����ˡ������������ǽ���˷����ݷֿ����� OpenAI �� Whisper ������ת��ΪӢ���ı����������Ѵʡ��٣�Spot������ϵͳ�ٽ����ı�������ʾ����
����ChatGPT ���ɻ����ı��Ļظ�֮����Ҫͨ���ı�ת����������������Щ�ظ����Ա�������ܹ�������ι��߶Ի����ڳ����˴�������ģ�espeak������ǰ�ص��о���bark���ȶ����ֳɵ��ı�ת����������ʿ�ٶ�������ѡ���� ElevenLabs��Ϊ�˼����ӳ٣����ǽ��ı��ԡ��������ʽ������ʽ����� TTS��Ȼ���в������ɵ���Ƶ��
�������һ�������Ϊ��Spot ����������һЩĬ�ϵ�֫�����ԡ�Spot �� 3.3 �汾���������ٻ�������Χ�ƶ�����Ĺ��ܣ�������������˺ͳ�����Χ�İ�ȫ�ԡ���ʿ�ٶ���ǡ�����������ϵͳʹ��²�������˵�λ�ã�Ȼ���ֱ�ת���Ǹ��ˡ����������ɵ�������ʹ���˵�ͨ�˲�����������ת��Ϊ��е�۹켣��������ľż����˵������ʽ���ر����ڻ�е�������ӷ�װ�͵ɴ���۾�֮�����ִ����õ��˼�ǿ��
|
 ������ҳ��
������ҳ�� 
 ����Ŀ
����Ŀ