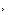|
科学怪鱼国语如果我们再次增加一个来自外界的刺激比如智能体的动作,就得到了马尔可夫决策过程(MDP)
在马尔可夫决策过程中, (S是状态的集合)和 (R是奖励的集合)的每个可能的值出现的概率只取决于前一个状态 和前一个动作 (A是动作的集合),并且与更早之前的状态和动作完全无关
换言之,当给定当前状态 (比如 ),以及当前采取的动作 (比如 ),那么下一个状态 出现的概率,可由状态转移 概率矩阵表示如下
考虑到在当前状态 和当前动作确定后,那么其对应的即时奖励则也确定了 ,故sutton的RL一书中,给的状态转移概率矩阵 类 似为
至于过程中采取什么样的动作就涉及到策略policy,策略函数可以表述为函数(当然,这里的跟圆周率没半毛钱关系)
此外,还会有这样的表述:,相当于在输入状态确定的情况下,输出的动作只和参数有关,这个就是策略函数的参数
通 过上文,我们已经知道不同状态出现的概率不一样(比如今天是晴天,那明天是晴天,还是雨天、阴天不一定),同一状态下执行不同动作的概率也不一样(比如即便在天气预报预测明天大概率是天晴的情况下,你大概率不会带伞,但依然不排除你可能会防止突然下雨而带伞)
相当于对当前状态S依据策略执行动作得到的期望回报,这就是大名鼎鼎的Q函数,得到Q函数后,进入某个状态要采取的最优动作便可以通过Q函数得到
当有了策略、价值函数和模型3个组成部分后,就形成了一个马尔可夫决策过程(Markov decision process)。如下图所示,这个决策过程可视化了状态之间的转移以及采取的动作。
且通过状态转移概率分布,我们可以揭示状态价值函数和动作价值函数之间的联系了
在使用策略时,状态S的价值等于在该状态下基于策略采取所有动作的概率与相应的价值相乘再求和的结果
而使用策略时,在状态S下采取动作的价值等于当前奖励,加上经过衰减的所有可能的下一个状态的状态转移概率与相应的价值的乘积
针对这个公式 大部分资料都会一带而过,但不排除会有不少读者问怎么来的,考虑到对于数学公式咱们不能想当然靠直觉的自认为,所以还是得一五一十的推导下
想在NLP领域更系统、深入提升的同学,我建议你看下【NLP高级小班 第十一期】
考虑到市面上课程大都以讲技术、讲理论为主,鲜有真正带着学员一步步从头到尾实现企业级项目的高端课程,故我们让大厂技术专家手把手带你实战大厂项目。一方面,让大家更好的在职提升,另一方面,力求让每位同学都深刻理解NLP的各大模型、理论和应用。
五大技术阶段:分别从NLP基础技能、深度学习在NLP中的应用、Seq2Seq文本生成、Transformer与预训练模型、模型优化等到新技术的使用,包括且不限于GPT、对抗训练、prompt小样本学习等
八大企业项目:包括机器翻译系统、文本摘要系统、知识图谱项目、聊天机器人系统,以及基本文本的问答系统、FAQ问答机器人、文本推荐系统、聊天机器人中的语义理解
对于技术阶段,新增文本检索系统中的关键技术以及22年年底爆火的ChatGPT原理解析
面向群体:本课程适合已经在做AI的进一步在职提升,比如在职上班族跳槽涨薪/升职加薪,采用严格筛选制(通过率不到1/3),需要具备一定的基础能力才能报名通过,故以下同学优先:
【NLP高级小班 第十一期】已开营,放5个免费试听名额,有意找苏苏老师(VX:julyedukefu008)或七月在线其他老师申请试听了解课程
|
 返回首页
返回首页 
 栏目文章
栏目文章